Building a GPU SaaS Platform - Activator Dispatch
/ 6 min read
In Part 13, we finally gave serverless requests a durable entrypoint. Every invocation now enters NATS JetStream before any worker executes it.
That solved the ingress side of the problem, but it still left one important gap:
who turns one queued invocation into work for one concrete worker?
So Part 14 introduces a stricter boundary.
The activator becomes its own process, and the worker side is split into two roles:
- the sidecar owns NATS consumption and publication
- the framework only talks to the sidecar over a local protocol
Chapter Goal
By the end of Part 14, the project has four new properties:
- a standalone
activatorprocess consumes durable ingress invocations from JetStream - the activator keeps a ready worker registry keyed by
serverless.requestIDand can create a newGPUUnitwhen no ready worker exists - the activator publishes worker-targeted dispatch messages instead of calling the user workload directly
- the runtime and the series now have an explicit worker-side split: sidecar owns NATS, framework owns only local request handling
Why The Framework Must Not Touch NATS Directly
It is tempting to say: if the worker already needs to run user code, why not let the user container consume NATS and publish results itself?
Because that collapses the trust boundary.
The moment the user workload has queue credentials and subject knowledge, it can:
- publish fake completion events
- forge metrics
- send messages outside its own request domain
- bypass platform-side validation and lifecycle controls
So the worker side needs one more split.
The sidecar is the only component allowed to touch NATS. The framework only speaks to the sidecar over an internal protocol such as UDS or localhost HTTPS.
That means:
- the activator trusts only sidecar-facing dispatch subjects
- the sidecar owns queue credentials and message publication
- the framework only sees the local request/response contract
- the user code never gets raw NATS access
This is the same general idea we use elsewhere in platform design: push the trusted transport and credential logic outward, and keep the user code on the narrowest possible interface.
The Full Architecture
At this point, the intended request path looks like this:
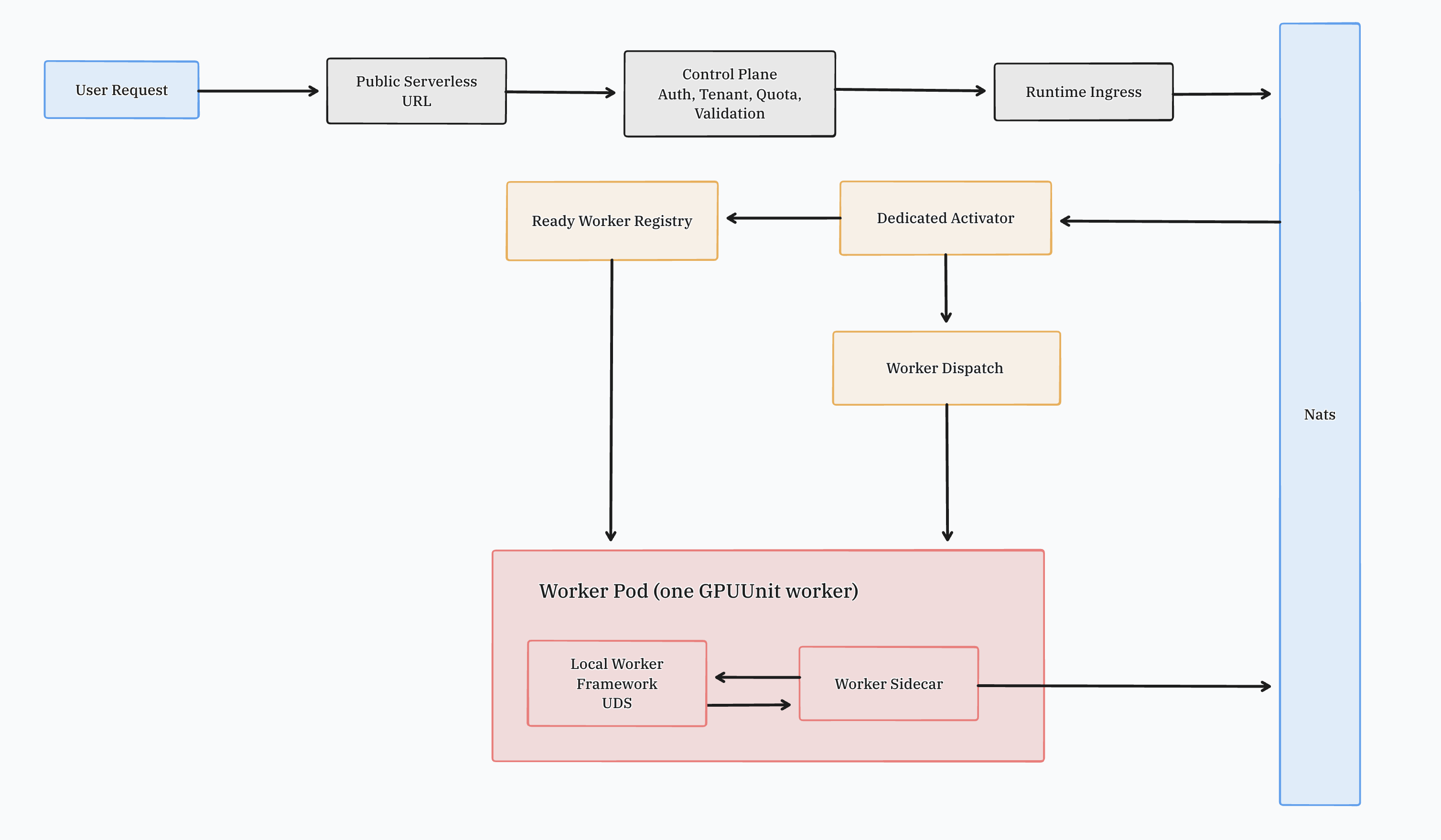
In concrete subject names, those three queue layers are:
- ingress:
runtime.serverless.invoke.<requestID> - worker dispatch:
runtime.serverless.dispatch.<requestID>.<workerName> - worker outputs:
runtime.serverless.result.<requestID>andruntime.serverless.metrics.<requestID>
The important part is the trusted boundary in the worker Pod:
activator -> dispatch subject -> sidecarsidecar -> local framework -> user handlersidecar -> result / reply / metrics subjects
The framework never consumes JetStream itself. It only handles local execution.
The Request Path Now
With that split in place, the intended runtime-side path becomes:
- the user calls one public serverless URL owned by the control plane
- the control plane validates auth, tenant, quota, and request shape
- the validated invocation is forwarded into the runtime-facing ingress path
- the runtime manager persists the invocation to
runtime.serverless.invoke.<requestID> - the activator consumes that ingress message
- the activator looks for one ready worker for the same
requestID - if no ready worker exists, the activator can clone a new
GPUUnitfrom an existing serverless worker template and wait for it to become ready - once a target worker is known, the activator publishes a worker-targeted dispatch message such as
runtime.serverless.dispatch.<requestID>.<workerName> - the worker sidecar consumes that dispatch message, calls the local framework, and then publishes the result, sync reply, and metrics back into NATS
This chapter stops at step 8 in code, but it also defines step 9 as the worker-side boundary we want to preserve.
That matters because it prevents us from writing the next chapter in a way that later becomes insecure.
What “Worker Registration” Means In This Chapter
For this chapter, worker registration is intentionally simple.
The activator keeps an in-memory registry of ready workers keyed by serverless.requestID.
Whenever it syncs matching GPUUnit objects, it registers workers that satisfy three conditions:
spec.serverless.enabledis truespec.serverless.requestIDmatches the invocation- the unit is
Ready
This is not yet a distributed coordination system. There is no shared lease store. There is no cross-activator lock.
That is fine for now.
The important point is that worker selection is now owned by the activator, even though the worker execution still belongs to the future sidecar and framework loop.
Where New Workers Come From Before Lifecycle Logic Exists
Part 14 still does not implement full prewarm or idle scale-down policy.
That matters because, if there are zero workers and zero templates, the activator has nothing to create from.
So this chapter uses a deliberately practical rule:
- at least one serverless
GPUUnitfor a givenrequestIDmust already exist - the activator can treat that unit as the template for later clones
In other words, the activator is not inventing worker configuration from scratch. It is reusing the existing runtime contract:
specName- image
- runtime template
- access contract
- SSH settings
- storage mounts
- serverless policy
That is enough to support worker creation without bypassing the existing stock handoff model.
What Changed In The Code
The new activator binary lives at:
cmd/activator
It loads local YAML config from:
config/local/activator.yaml
The activator logic lives in:
pkg/activator
That package now owns:
- ready worker discovery by
serverless.requestID - worker creation by cloning an existing serverless
GPUUnit - worker-ready waiting
- worker-targeted dispatch publication
- failure-result publication when dispatch cannot proceed
The shared queue contract in:
pkg/serverless
now grows one more durable message type:
WorkerDispatchMessage
and one more subject family:
runtime.serverless.dispatch.<requestID>.<workerName>That is the key architectural change.
Before this chapter, the serverless queue path ended at ingress. After this chapter, the activator can turn one ingress invocation into one worker-targeted dispatch message, while still keeping the worker-side trust boundary intact.
The public runtime API remains:
POST /api/v1/serverless/invocationsThat endpoint still owns the queue-first ingress rule. The activator just becomes the next process in the path.
Verification
There are four useful checks after implementing this chapter.
1. Start NATS, the runtime manager, and the activator
NATS:
nats-server -jsManager:
GOTOOLCHAIN=go1.26.0 go run ./cmd/main.go --config config/local/runtime-manager.yamlActivator:
GOTOOLCHAIN=go1.26.0 go run ./cmd/activator --config config/local/activator.yaml2. Ensure one serverless worker template exists
This chapter still expects at least one serverless GPUUnit for a given requestID.
curl -s -X POST http://127.0.0.1:8080/api/v1/gpu-units \
-H 'Content-Type: application/json' \
-d '{
"operationID":"unit-sd-webui-001",
"name":"sd-webui-template",
"specName":"g1.1",
"image":"python:3.12",
"template":{
"ports":[{"name":"http","port":8080}]
},
"access":{
"primaryPort":"http",
"scheme":"http"
},
"serverless":{
"enabled":true,
"requestID":"sd-webui",
"minAvailableCount":1,
"idleTimeoutSeconds":300,
"minRequestCount":0
}
}' | jq3. Publish one async invocation
curl -s -X POST http://127.0.0.1:8080/api/v1/serverless/invocations \
-H 'Content-Type: application/json' \
-d '{
"serverlessRequestID":"sd-webui",
"mode":"async",
"attributes":{
"path":"/generate",
"method":"POST"
},
"payload":{
"prompt":"draw a robot"
}
}' | jqYou should see a durable enqueue acknowledgement from the manager.
4. Inspect the activator logs
At this stage, the best verification point is the activator log. You should see it:
- consume the ingress invocation
- resolve or create a ready worker
- publish one worker-targeted dispatch message
The worker sidecar and local framework loop will consume that dispatch subject in the next chapter.
Summary
Part 14 is where the serverless queue path stops being only ingress and starts becoming a real execution routing boundary.
We now have:
- a dedicated activator process
- ready worker discovery by
serverless.requestID - worker creation from an existing serverless
GPUUnittemplate - worker-targeted dispatch subjects
- a clear worker-side trust boundary where only the sidecar can touch NATS
That is a much healthier design than either of the two bad alternatives:
- letting the runtime manager own everything
- letting the user workload talk to NATS directly
The next chapter will stay inside the worker Pod and finish the other half of the design: the sidecar loop, the local framework contract, and the result or metrics publication path.
Next Chapter Preview
Part 15 will add the worker sidecar and the local framework contract. That chapter will consume the worker dispatch subjects, call the user handler through a narrow local interface, and publish results, sync replies, and metrics back into NATS.
Repository
Code for this chapter:
Comments
Join the discussion with your GitHub account. Powered by giscus .